 Competitive intelligence, the "what else", is one of the core tenets of Web Analytics 2.0.
Competitive intelligence, the "what else", is one of the core tenets of Web Analytics 2.0.
The reason is simple: The ecosystem within which you function on the web contains mind blowing data you can use to become better.
Your traffic grew by 6% last year, what was your competitor's growth rate? 15%. Feel better? : ) When should you start doing paid search advertising for tours to Italy for 2011? In May 2010 (!). What is your "share of search" in the netbook segment compared to your biggest competitor? 9 points higher, now you deserve a bonus! How many visitors to your site go visit your competitor's site right after coming to yours? 39%, good god! Where to do display advertisements to ensure you get in front of men considering proposing to their girlfriends (or boyfriends)? Go beyond targeting men between the age of 28 and 34, use search behavior and be really smart.
I am just scratching the surface of what's possible.
It is simply magnificent what you can do with freely available data on the web about your direct competitors, your industry segment and indeed how people behave on search engines and other websites.
The secret to making optimal use of CI data lies in one single realization: You must ensure you understand how the data you are analyzing is collected.
Not all sources of CI data are created equal. It is key that before you use the data that comScore or Nielsen or Google or HitWise or Compete or your brother-in-law shove into your face that you understand where the data comes from.
Once you understand that you choose: 1. The best source possible that is 2. The right answer for the question you are asking (which implies you have to be flexible!).
Here are the sources of competitive intelligence data.
#1: Toolbar Data.
Toolbars are add-on's that provide additional functionality to web browsers, such as easier access to news, search features, and security protections. They are available from all the major search engines such as Google, MSN, Yahoo! as well as from thousands of other sources.
![]()
These toolbars also collect limited information about the browsing behavior of the customers who use them, including the pages visited, the search terms used, perhaps even time spent on each page, and so forth. Typically, data collected is anonymous and not personally identifiable information (PII).
After the toolbars collect the data, your CI tool then scrubs and massages the data before presenting it to you for analysis. For example, with Alexa, you can report on traffic statistics (such as rank and page views), upstream (where your traffic comes from) and downstream (where people go after visiting your site) statistics, and key-words driving traffic to a site.
Millions of people use widely deployed toolbars, mostly from the search engines, which makes these toolbars one of the largest sources of CI data available. That very large sample size makes toolbar data a very effective source of CI data, especially for macro website traffic analysis such as number of visits, average duration, and referrers.
Search engine toolbars are a ton more popular which is the key reason that other toolbars data sources, such as Alexa, are not useful any more (the data is simply not good enough).
Toolbar Data Bottom-line: Toolbar data is typically not available by itself. It is usually a key component in tools that use a mix of sources to provide insights.
#2: Panel Data.
Panel data is another well-established method of collecting data. to gather panel data, a company may recruit participants to be in a panel, and each panel member installs a piece of monitoring software. The software collects all the panel’s browsing behavior and reports it to the company running the panel. Additionally the person is also required to self report demographic, salary, household members, hobbies, education level and other such detailed information.
Varying degrees of data are collected from a panel. At one end of the spectrum, the data collected is simply the websites visited, and at the other end, the monitoring software records the credit cards, names, addresses, and any other personal information typed into the browser.
Panel data is also collected when people unknowingly opt into sending their
data. Common examples are a small utility you install on your computer to get the weather or an add-on for your browser to help you auto complete forms. in the unreadable terms of service you accept, you agree to allow your browsing behavior to be recorded and reported.
Panels can have a few thousand members or several hundred thousand.
You need to be cautious about three areas when you use data or analysis based on panel data:
Sample bias: Almost all businesses, universities, and other institutions ban monitoring software because of security and privacy concerns. Therefore, most monitored behavior tends to come from home users. Since usage during business hours forms a huge amount of web consumption, it is important to know that panel data is blind to this information.
Sampling bias: People are enticed to install monitoring software in exchange for sweep-stakes entries, downloadable screensavers and games, or a very small sum of money (such as $3 per month). This inclination causes a bias in the data because of the type of people who participate in the panel. This is not itself a deal breaker, but consider whose behavior you want to analyze vs. who might be in the sample.
Web 2.0 challenge: Monitoring software (overt or covert) was built when the Web was static and page-based. The advent of rich experiences such as video, Ajax, and Flash means no page views, which makes it difficult for monitoring software to capture data accurately. Some monitoring software companies have tried to adapt by asking companies to embed special beacons in their website experiences, but as you can imagine, this is easier said than done (select few want to do it, then do they do it well and how do you compare companies that did or did not beaconify?).
The panel methodology is based on the traditional television data capture model. In a world that is massively fragmented, panels face a huge challenge in collecting accurate and complete (or even representative) data. A rule of thumb I have developed is if a site gets more than 5 million unique visitors a month, then there is a sufficient signal from panel-based data.
Panel Data Bottom-line: For companies such as comScore and Nielsen panel data has been a primary source for competitive reporting they provide their clients. But because of the methodology's inherent limitations, recently panel data is augmented by other sources of data before it is provided for analysis (including for a subset of data you'll get from comScore and Nielsen – please check & clarify before you use the data).
#3: ISP (Network) Data.
We all get our internet access from Internet Service Providers (ISP's), and as we surf the Web, our requests go through the servers of these ISP's to be stored in server log files.
The data collected by the ISP consists of elements that get passed around in URLs, such as sites, page names, keywords searched, and so on. The ISP servers can also capture information such as browser types and operating systems.
The size of these isps translates into a huge sample size.
For example, Hitwise which chiefly relies on isp data, has a sample size of 10 million people in the United states and 25 million worldwide. Such a large sample size reduces sample bias (surprise!). There are also geographically focused competitive intelligence solutions, like Netsuus in Spain, that provide analysis from excellent locally sourced data.
The other benefit of ISP data is that the sampling bias is also reduced; since you and I don’t have to agree to be monitored, our ISP simply collects this anonymous data and then sells it to third-party sources for analysis.
ISP's typically don’t publicize that they sell the data, and companies that purchase that data don’t share this information either. So, there is a chance of some bias. Ask for the sample size when you choose your ISP-based CI tool, and go for the biggest you can find.
ISP Data Bottom-line: The largest samples of CI data currently available comes from ISP data (in tools like Hitwise and Compete). Though both tools (and other smart ones like them) increasingly use a small sample of panel data and even some small amount of purchased toolbar data.
#4: Search Engine Data.
Our queries to search engines, such as Bing, Google, Yahoo!, and Baidu, are logged by those search engines, along with basic connectivity information such as IP address and browser version. In the past, analysts had to rely on external companies to provide search behavior data, but increasingly search engines are providing tools to directly mine their data.
You can use search engine data with a greater degree of confidence, because it comes directly from the search engine (doh!). Remember, though, that the data is specific to that search engine—and because each search engine has distinct user base, it is not wise to apply lessons from one to another.
With that mild warning here are some amazing tools. . . .
In Google AdWords, you can use Keyword Tool, the Search-based Keyword Tool and Insights for Search.
Similar tools are available from Microsoft: Entity Association, Keyword Group Detection, Keyword Forecast, and Search Funnels (all at Microsoft adCenter Labs).
Search Engine Data Bottom-line:Search engine data tends to be the primary, and typically the best source you can find, for search data analysis. If you are analyzing data for your SEO or PPC campaigns and you find the search engine providing the data then you should instantly embrace it and immediately propose marriage!
#5: Benchmarks from Web Analytics Vendors.
Web analytics vendors have lots of customers, which means they have lots of data. Many vendors now aggregate this real customer data and present it in the form of benchmarks that you can use to index your own performance.
Benchmarking data is currently available from Fireclick, Coremetrics, and Google Analytics. Often, as is the case with Google Analytics, customers have to explicitly opt in their data into this benchmarking service. But this is not always true for all vendors, please check with yours.

Both Fireclick and Coremetrics provide benchmarks related to conversion rates, cart abandonment, time on site, and so forth. Google Analytics provides benchmarks for visits, bounce rates, page views, time on site, and % new visits.
In all three cases, you can compare your performance to specific vertical markets (for example, retail, apparel, software, and so on), which is much more meaningful.
The cool benefit of this method is that websites directly report very accurate data, even if the web analytics vendor makes that data anonymous. The downside is that your competitors might not all use the same tool as you; therefore, you are comparing your actual performance against the actual performance of a subset of your competitors.
With data from vendors, you must be careful about sample size, that is, how
many customers the web analytics vendor has. If your web analytics vendor has just 1,000 customers and it is producing benchmarks in 15 industry categories, it might be a hit or a miss in terms of how valuable / representative the benchmarks are.
WA Vendor Data Bottom-line: Data from web analytics vendors comes from their clients, so it is real data. The client data is anonymous, so you can’t do a direct comparison between you and your arch enemy; rather, you’ll compare yourself to your industry segment (which is perfectly ok).
#6: Self-reported Data.
It is common knowledge that some methods of data collection, such as panel-
based, do not collect data with the necessary degree of accuracy. A site’s own analytics tool may report 10 million visits, and the panel data may report 6 million. To overcome this issue, some vendors, such as Quantcast and Google’s Ad Planner, allow websites to report their own data through their tools.
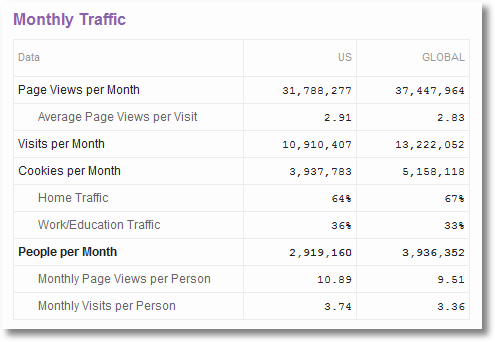
For sites that rely on advertising, the data used by advertisers must be as
accurate as possible; hence, the sites have an incentive to share data directly. If your competitors publish their own data through vendors such as Google’s Ad planner or Quantcast, then that is probably the cleanest and best source of data for you.
One thing to be cautious about when you work with self-reported data. Check the definitions of various metrics. For example, if you see a metric called Cookies, find out exactly what that metric means before you use the data.
Self-Reported Data Bottom-line: Because of its inherent nature, self-reported data tends to augment other sources of data provided by tools such as Ad Planner or Quantcast. It also tends to be the cleanest source of data available.
#7: Hybrid Data (/All Your Base Are Belong To Us).
Competitive intelligence vendors are observing you from the outside. Any single source, toolbar or panels or isp or tags or spyware etc, will have its own bias / limitation.
Some, smart, vendors now use multiple sources of data to augment the data set they started their life with.

The first method is to append the data. This is what's happening in the case of Quantcast and Google Ad Planner, in both cases they have their own source of data to which your self reported data is added. The resulting reports are "awesomely good".
The second method is to put many different sources (say toolbar, panel, isp) into a blender, churn at high speed, throw in a pinch of math and a dash or correction algorithms, and – boom! – you have one "awesomely good" number. A good example of this is Compete or the DoubleClick Ad Planner.
Google's Trends for Websites is another example of a tool that uses hybrid data for its reporting (see answer #2 here).
The benefit of using hybrid methodology is that the vendor can plug in any gaps
that might exist between different sources.
The challenge is that it is much harder to peel back the onion and understand some of the nuances and biases in the data (sometimes mildly frustrating to analysis ninja's such as myself!).
Hence, the best-practice recommendation is to forget about the absolute numbers and focus on comparing trends; the longer the time period, the better.
Hybrid Data Bottom-line: As the name implies, hybrid data contains data from many different sources and is increasingly the most commonly used methodology. It will probably be the category that will grow the most because frankly in context others look rather sub optimal.
[Update:] #8: External Voice of Customer Data.
This is one often overlooked source of competitive intelligence (/benchmarking) data. There are several ways to use Voice of Customer data.
For starters various companies such as iPerceptions (like CoreMetrics, Google Analytics, Fireclick above for clickstream) publish Customer Satisfaction & Task Completion Rate (my most beloved metric!) numbers for various industries.
If I am in the internet retail game I can use these benchmarks to compare my performance:

Or I can dig deeper and compare my performance by the Primary Purpose segments:
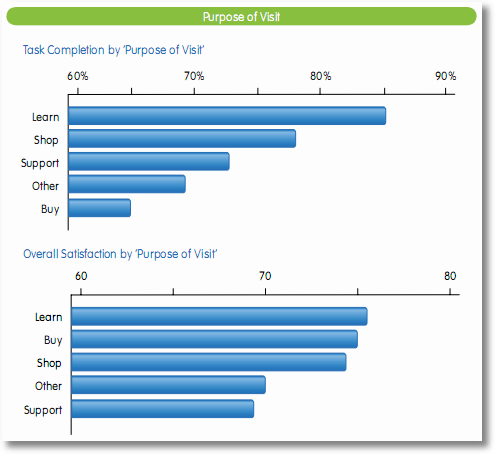
Both of the above are from the iPerceptions Q4 2009 Ecommerce Benchmark report. You'll find other reports in the Resource Center.
With other sources like the ACSI (American Customer Satisfaction Index) you can get a big deeper. Just choose an industry from their site, I choose Internet Travel, and bam!

If I am Travelocity I am wondering what in the name of Jebus did the other guys do last year to have all those gains in Satisfaction where I got a zero.
And really what are those guys at Priceline eating! 5.6 points improvement just last year, 15 points over the last 9! Sure they started with a smaller number but still.
What can I, sad Travelocity, learn from them? From others?
In both cases above the intelligence came from a third party doing the research and giving you data for free.
But you can also commission studies, from the two companies above or one of thousands like them on the web.
Or you can do it yourself.

I just met a Top Web Company the other day and I spent $300 on 20 remote usability participants to go to the website of Top Web Company and their main competitor. I gave the usability participants the exact same tasks to do on both sites.
The scores were most illuminating (and embarrassing for Top Web Company). It allowed me to (without working at either company) collect competitive intelligence about how each were delivering against: 1. Task Completion Rate and 2. Customer Satisfaction.
You could collect your own competitive intel using UserTesting.Com, User Zoom, Loop11, or one of many other tools.
Or for even "cheaper" (and a bit less impactful) insights you can use something delightful like www.fivesecondtest.com. Upload how your pages, upload those of your competitors (or complete strangers not in your industry) and learn from real users which designs they prefer and what works best.
Hybrid Data Bottom-line: I love customers, I love Task Completion Rate as a powerful metric, I love VOC. Above are three simple ways in which you can collect competitive intelligence using Voice of Customer data and drive action perhaps even faster than the first seven methods!
[PS: Nothing, absolutely nothing, works better to win against HiPPOs than using competitors and customers!]
The Optimal Competitive Analysis Process.
A lot of data is available about your industry or your competitors that you can
use to your benefit.
Here is the process I recommend for CI data analysis:
1. Ensure that you understand exactly how the data is collected.
2. Understand both the sample size and sampling bias of the data reported to you. Really spend time on this.
3. If steps 1 and 2 pass the sniff test, use the data.
Don’t skip the steps, and glory will surely be yours.
See the additional posts linked to below for types of analysis you can do once you choose the right tool [OR you can also start on page 221 of my new book Web Analytics 2.0!].
Ok now your turn.
Do you use a source of competitive intelligence data not covered in this blog post? Which of the above 7 is your favorite? Was there something surprising you learned in this post? What is one thing you would add to the critical analysis above?
Please share your tips, best practices, critique in comments.
Thanks.
PS:
Couple other related posts you might find interesting:
- Competitive Intelligence Analysis: Metrics, Tips & Best Practices
- Paris Hilton, Kim Kardashian & Telling Stories With Data
- Competitive Intelligence Analysis: Google / DoubleClick Ad Planner
- Competitive Intelligence Analysis: Google Insights for Search
- Competitive Intelligence Analysis: Google Trends for Websites
- Google’s Search Based Keyword Tool





 Via
Via 














Aha! Finally you've touched my favorite topic. THANK YOU! I started off my career as a market researcher. Panels/ Focus group, though very effective in the past, makes me nervous due to the possibility of huge sampling error, as you rightly pointed out. My favorite is still search engine data and of course GA's benchmark. One challenge I sometimes face with clients is having them to agree to submit their data to Google.
Great post!
-Bibi
I would say that Panel Data is something that I've never used…probably because I've never worked for comScore or Nielsen :)
My favorites are Google Insights for Search, Google Trends (for Websites) and I really like Hitwise's Upstream / Downstream reports. They're like the Path analysis reports for your web site, except they are at the user-session level.
I was looking at some numbers on Compete just last Friday and thinking "I have to find out where their data comes from"… so you must have read my mind Avinash :) Thanks for the post!
Love this post. I used Competitive Intelligence for a client after reading about it in your Web Analytics 2.0 book. (which is a must read!)
The tool I have come to love is Google Trends. Getting an idea of when customers are looking for a specific type of product is an awesome thing to have.
Excellent post. I've been waiting for Google to come out with a public Competitive Intelligence service similar to Alexa, but much more reliable since they have so many more data sources to draw from. Instead of the antiquated toolbar PageRank which is from 0-10, it would be nice to see Google provide an actual "GoogleRank" number from 1-1,000,000,000 for all sites.
A very timely post for me. I use Google Benchmarking, Google Trends, Google Insights for Search, and CoreMetrics benchmarking data but our agency is considering bringing in a paid competitive intelligence tool we can use to provide greater context to our client performance data. I like what I see from Compete and based on the information you've shared here I am leaning a little harder in that direction. Thank you for pulling together all my considerations into one, very focused, analysis.
A great post that reminds us all to "consider the source".
Thanks Avinash!
Perfect timing! I'm working on a presentation about Social Media vs SEO competitive intelligence for the Portland SearchFest next month- this will stimulate my brain cells. Thanks :-)
Just for "color," I'll play Devil's Advocate here:
— I think there is often very little non-obvious learning from "competitive data"
— Chasing competitive secrets feels like a formula for ending up a distant 2nd! (if you're lucky)
It is my POV, that most CI data is only accurate on the most common, most obvious aspects (biggest sites, biggest competitors, biggest KWs, etc.). There is often little/no data on smaller, less obvious trends. If these systems typically point out of the obvious, how useful are they? Is obvious (and potentially inaccurate) data worth a fee? Is it worth the time?
For some fun, run a CI report on *your own business*… when it doesn't really reflect what you're actually doing, CI will lose some luster.
CI data is great "client crack." If you need to dazzle execs, they eat this stuff up… but I can't really say that any meaningful % of success has come from "all the secrets (!)" I've seen about my comp over the years.
CI is an "idea" game, when most of us already have enough ideas. To Avinash's point… the 90/10 rule applies here to!
Cheers!
[G
DroidINDUSTRIES.com
I just spent a week slogging through industry reports (a particular niche of luxury goods). A lot of the data I was getting did not agree. I suppose it would be easy to choose the data that best supports the points I'm trying to make in my presentation- or I can (as I chose to) err on the side of the most conservative data.
In particular, Compete.com data seemed really out of wack. To a point where if I had presented the data I got from it, and had been called upon to verify the data, it would have been an absolute embarrassment.
Typically, I find that we get comfortable with a particular tool set, then use the others just to sniff out anomalies. If anomalies are found, then its worthwhile to invest the time into verifying the data.
Bibi: I normally educate people that there are three data sharing (privacy) settings in Google Analytics:
1. Share data with Google anonymously. This means your data is shared but Google does not know what site's data it is. This should get your benchmarks and all that other stuff.
2. Share data with Google named. This means your data is shared with Google and it knows it is website bibi.com. This is helpful for various automated conversion optimization type things.
3. Do not share my data with Google. This means that no one at Google can look at your data and it is only accessible to you.
I find people are surprised that they have this much control over what happens to their data, and then they make an informed decision rather than based on FUD spread by others.
If the decision is not to share the data with Google (and hence not get benchmarking etc) that is ok. You can still use other resources like FireClick and CoreMetrics and all that to get benchmark data at some level to your clients. The important thing is to use the data. :)
Joe: There is a upside to panel data, there is no other source of demographic and psychographic information. The end users have to report it to the vendor (or well hook up a nice pipe to the data the NSA has on all of us, but that might be a career limiting move!).
My caution is to treat that data carefully and to read just as much as it deserves into it. Sadly 99% (only slight exaggeration) of current display ads (and now social ads) are purchased purely off demographic self reported panel data. That is sadly a great way to waste money, not a great way to present relevant ads to your audience.
Streamline: I suspect people from Google read the post and in as much will be happy to get your feedback. Though I am personally not sure that straight ranking sites provides much of value (given the astonishing diversity that exists on the web in types of websites).
Guy: I am afraid I have to disagree with your devil advocacy! Kidding.
I have covered many practical real world cases of how to use this data. Please click on any of the links at the end of my blog post, any one, and you'll see them.
I have to fess up two things: 1. I think comparing conversion rates is a waste of time (I have covered why in the past). 2. Comparing your own data to the CI data for your site is a waste of time and misses the value of the ecosystem data.
Ric: One of the primary reasons behind this post was to encourage understanding of and use of optimal source to answer the question at hand. For example I use a different tool if I was website traffic trends (and even there two different ones depending on how big the site is), search keyword research, demographic info etc etc.
In as much one tool may be good thing but not so good at another. For example my experience with Compete is very good in both search analytics and website analytics. But I would use Ad Planner for demographic questions.
Avinash.
"1. I think comparing conversion rates is a waste of time"
People look at me like I'm from 14 trillion light years away when I say something like this. Good to know I'm not the only one who feels this way. And, it makes sense that comparing CI data to you own site's data is also a waste of time.
Hi Avinash, thanks for your post, this is a complete list of Competitive Intelligence Sources. I agree 100% with you "Ensure that you understand exactly how the data is collected." I tried to publish something similar in spanish some days ago but your post reached the maximum level of 'sexy' compared with mine as usual :-). I leave here the link for those who wants to check it :-) http://clotet.wordpress.com/2008/04/10/sistemas-de-medicion-de-trafico-en-internet/
Hope to see you soon, Jaume
Hey Avinash > here's some (kicking /rocking !!) learning to share as promised. :)
Would say we have to based whatever competitive intelligence data with a grain of salt and utilizing it as a alternative "trend monitoring tool" on:
1. Traffic (spikes or decrement) of competitors
Why the spike or decrement ? i.e. Did they increase / decrease their paid search ? Did they revamp their site ? Did they add in new content ? etc
2. Wayback Machine (another CI tool to consider)
Another tool we could tapped into – why you say ?
Following onto point 1 > we can quickly tapped into what triggers the spike or decrement – is it because of a certain content change ? Testing going on ? etc
Ok hope I do rock everyone to consider an alternative in tapping on and utilizing CI data source :)
Great summary Avinash
Another limitation to add to panel data is sample geolocation – from my experience, unless you are are looking for data based in the US or UK, forget it. The sample sizes are so small – 1000 was quoted to me for Sweden by one panel vendor which has 8m highly savvy Internet users (90% population penetration) – and the extrapolations such a guestimate, that the numbers were useless…
I wrote this post a year ago for an online newspaper that was wrestling with the debate of on-site/off-site web analytics accuracy:
http://www.advanced-web-metrics.com/blog/2009/02/22/improving-the-web-with-web-analytics/
Best regards, Brian
I have used most of these tools and I must say each one is needed to do a good analysis. What surprises me every time is how people higher up in the organisation asks for either black or white, and the more tool you use the harder it is to present the truth in black and white. :)
Avinash,
Great article. As a web analyst I'm often facing the vast differences in CI data as you point out. Through my experiences, I've concluded that no single source can be taken at face value, because, as you say, the collection method influences the results.
The best solution, I've determined, is to combine data from multiple sources (picking CI providers that acquire data in multiple fashions). This allows us to get high/low/medium values that we can use to monte carlo the data and come to a 'most likely' scenario. I would encourage others to take a similar approach and combine data sources rather than stick to any one CI solution.
Theodor: I agree with you 100%.
Even if we, the Ninja's, get it and start using the tools at our disposal, it is very hard to get the HiPPO's to see things in an optimal fashion.
But I am convinced the world will have to change. Multiplicity is the only way to win now!
B Weiss: That is a very interesting approach, thanks for sharing it!
I have to admit that for metrics like say Visits or Visitors this might provide value.
For others, like say Share of Search or how best to target audiences based on behavior, there is one source that will be better than others and in those cases I recommend people take time to dig into how data is collected and just use that one source. [Else my small fear is we'll use math to rationalize the unrationalizable!]
Thanks again,
Avinash.
Hi Avinash,
Thanks for the article! Comscore has come out with the "media metrix 360 hybrid measurement" product, which combines panel data with site server web analytics data, by forging an alliance with omniture. As summed up by you (quote unquote) "Hybrid Data Bottom-line: As the name implies, hybrid data contains data from many different sources and is increasingly the most commonly used methodology. It will probably be the category that will grow the most because frankly in context others look rather sub optimal.", would this alliance pose a threat to search engine data sources and become a potent alternative.
Would much appreciate your views on the same…
Thanks
Sudhir
Avinash,
First of all, thanks for the great post. It's a shame that some folks show distrust for competitive intelligence because it's either free, cheap or somewhat inaccurate (especially when they've relied on other inaccurate data they've paid for in the past!). I think your point of understanding not only the data, but how it was produced, is something many still struggle with. But it's great that you're sharing these tools as a way to pave the path.
Sudhir: Hybrid is certainly the way to go. For far too long comScore's data collection methodology suffered from gaps that were primarily caused because the web is massive and massively diverse (purpose, consumption, type, geo, devices….) and methodologies that worked on TV don't work online.
As you analyze sources with "self reported data" [quantcast – self reported (permission based), comScore – contributed via Omniture (permission based?), AdPlanner – contributed via Google Analytics (permission based)] it is important to check if the company / industries you are analyzing are reporting their website data into the tool you are using.
For example if your direct competitor/'s is not using Omniture then analyze if comScore is still the best source, if they are using Omniture check if they are contributing their data to comScore etc. You would do this with any tool you use, not just comScore.
With regards to if hybrid data (from any source) would "pose a threat" to search engine data sources…. consider this: If you want to analyze search data why would a third party observed data be better than data provided by the source (Google, Baidu, Microsoft etc)?
My above question of course only applies to search data and not the other types of CI data for which you'll of course use other CI tools.
Avinash.
Avinash,
Thank you for your reply and for the valuable insights. Btw, i religiously follow all your posts and would like to commend you on the painstaking research of data sources, channels, free tools available etc. in web analytics and its dissemination to a large audience.
FYI: I purchased yesterday your latest book "Web Analytics 2.0: the art of online accountability……" – which i'm sure would make for exciting reading, like all your blog posts, and maybe come back to you with more comments/questions etc.
Avinash,
How about alternatives for sites outside the USA since most of the users and data for these CI tools (especially compete) is USA focused?
Google Trends/Insights – OK, but are there any others with reliable data?
Thanks!
Thanks Avinash for your insights. Learning about the availability of sites such as usertesting.com is a real eye opener for me, working in the small to medium size business market, I'm sure that you have helped me in a big way to add some more value to my clients.
However, I'm another one wondering whether for my clients here in the UK these kind of US based services are going to be as valid and helpful? And do we want the features of the world's websites homogenized by a limited group of testers in the US? Just a thought.
Thanks again for a wonderful blog and books.
Wow, very great in-depth analysis and conclusions to your points. A lot of great information in here and it's very concise.
Thanks for the post!
Iain [& Michael]: Good point Iain, one must be careful about which tool to use when you are looking at countries outside the US.
Some of the 8 data sources mentioned in the blog post won't work in some local areas (as you point out panels based methods particularly stink at non-US data) and some tools won't work (compete.com for example is not to be used for visitors outside the US because they make it very clear on their site they are only reporting on US traffic – you can get US traffic to a Italian site though).
There are ISP and hybrid tools that now cover a huge part of the world.
For example in Spain my friend Jaume's company Netsuus (http://www.netsuus.com/) is an excellent source.
In terms of a hybrid source if you use Trends for Websites then you can get pretty good data for most countries (of course in the limited number of metrics it provides), for example here is my focusing just on the UK traffic of Marks & Spencer:
http://zqi.me/aj2Dpj
HitWise has always had a very good foot print in Australia and the UK.
So on and so forth. Pays to dig a bit deeper and investigate other companies and how they collect data.
-Avinash.
Absolutely amazing post and just what I needed. I love the meta aggregation thoughts and it's where I'm going with my own work.
I have no grains of salt to add, nor any criticisms. I shall only say, You, Avinash, are awesome.
I will say this: using Google Trends and Google Insights for search is a great combo. Combine with external Adwords tool and it's a recipe for trending. Anyone with any thoughts on the verity of Insights, though? I know the data is *relative*, but it still seems crazy useful, especially when getting to the 'ideation of new work phase for the client' – it's an impressive display of juicy ideas… and in a way that's how I read this article – it's PROOF for future projects for my clients.
Avinash,
Great post, am reading WA 2.0 now and learning a ton. Thank you.
Quick Q for your or the group: In the post, it states "…The largest samples of CI data currently available comes from ISP data (in tools like Hitwise and Compete). Though both tools (and other smart ones like them) increasingly use a small sample of panel data…"
On Compete's site, they downplay ISP partnerships and make it sound like their "panel" is their differentiator. Is this just semantics, or does compete only integrate marginal ISP data?
Avinash,
I know I'm coming to the party way late in responding to this one. Great post. Interesting topic. I agree with all of your points. One of the things that I've learned is that the HIPPOs do get caught up in comparing the numbers coming from CI tools to the numbers coming from the web analytics tools. One piece of advice that was given to me on this topic was to try to shield them from the actual data and just report to them the % difference between where they are and where you are. (EX: Company Y had 22% fewer visits to their website than ours) By avoiding the use of the actual numbers that the CI tool is reporting, you can avoide the comparisons.
Other excercises I'e done is compare my competitor's trends over time to see if their sites experience the same seasonality influences that mine experience.
Another thing that I've done is take a look at my industry and then assign each competitor to a segment of my industry. Then I sum the monthly performance of each member of an industry segment to see how that segment is performing and if there are any segment trends. An example might be auto sales. Possible websites may belong to Ford, Louie's used cars, Chevy, Honda, Cindy's Used cars, Hyundai and Max's used cars. So, I take the performance of Ford, Chevy, Honda, and Hyundai and sum them up for each month for an extended period of time and follow the trend. This is my new cars segment. I do the same for the used cars to get a sense of used car interest. Trending these leads to interesting observations. Had you done this, I'm sure you would have seen the increase in new car sales due to the clunker trade in offer. Doubt that used cars would have seen a spike then.
Just a couple of thoughts. Once again, great post!
Alice Cooper's Stalker
This is a really helpful article, Avinash.
As a self-taught, newly-hatched web geek, I've concentrated on learning how to design websites, write the copy, and incorporate meta-tags, alt tags, headings, links, etc. into my sites. Unfortunately, I haven't done much at all to measure the results.
Between your lecture at Inbound Marketing University and your blog, I am newly inspired and determined to tackle this piece next. Thank you.
Thanks for a great post – I think a lot of people who are not directly involved with Web Analytics should be forced to read this before they ask for any data.
By the way – what metrics would you suggest if your site is generally static -i.e. if its very, very stable and you are not seeing many trends. What does that mean?? Good or bad?
With data from vendors, you must be careful about sample size, that is, how
many customers the web analytics vendor has. If your web analytics vendor has just 1,000 customers and it is producing benchmarks in 15 industry categories, it might be a hit or a miss in terms of how valuable / representative the benchmarks are.
Avinash great point , as usual. When I first start reading I thought you were going to write about tools that help getting data form GA, as some plugins do.
I was well suprised about the complete range of the post. Excellent tools (some I alredy knonw)! Unfortunaly some of them just work in US.
In your experience what would be a good tool to analyze the data from CI? I haven't seen too much emphasize on this in any of the Site Analytics tools.
I guess Microsoft adCenter Labs is no longer around. Link didnt work.
Hi,
I think for the banking industry these two are the key fro me:
External Voice of Customer Data and Benchmarks from Web Analytics Vendors.
Many a times orginisations do so much but they forget to get feedback from the customer ( the reason they are in business).
Great article!
Loved the links, especially fivesecondtest.com, I'm going to test my websites NOW! :)
Hi Avinash –
Maybe you can be of some help…
I've been watching my Google Analytics Benchmarking data for the past two months and nothing ever shows up. Despite having checked the area "Anonymously with Google and others" within my account the benchmarking features in Google Analytics are still not visible.
Is any other area I should be checking to have it enabled? Am I missing something? I've done some research on this and many people appear to have the same problem but no one has answers.
Thanks for another great post!
Rachel
Rachel: The benchmarking reports mentioned in this post have been removed from Google Analytics. But fear not, there are new ones!
For the newest reports, and where to find them and what to do with them, please see this post:
~ Benchmarking Performance: Your Options, Dos, Don'ts and To-Die-Fors!
If you still can't see them (per your comment), check out how to specify your data sharing settings:
~ Google Analytics Data Sharing Setting
If you feel they are as described above, and you still don't see the reports. Change them to Not Sharing. Wait a couple days. Change back to Sharing. That sometimes triggers things back to normal (though clearly it should not!).
Avinash.
Hi Avinash, great to see a summary on CI.
While it is true the panel data have some selection biases, so do other, the digital data collections as you point out, but are not pointed out or discussed under bold faced section titles similar to the discussions on off-line panels.
Also, this is the reason why panels provide weights (well they should) or you can figure out the weights if you use a merge with a national database such as Acxiom/Experian, and you can address over or under sampling of sections of populations.
Very interestingly, you can not do that with any bias that are accruing in digital data collections, because there is no concept of weights or deeper adjustment processes in digital data (unfortunately so far). I do not mean to come out negative, and I trying to give a balancing statement here. Some time back you asked me to provide input/critique, instead of just appreciating words. Here it is. I love your posts and becoming a student of your site and so you will find more of my input.
None the less, a great post.
BTW, the typing area is difficult to type and check out, as it moves all the way to the left, right, bottom,…; Not sure what you can do; just thought you might like to hear out…kind of annoying…
Best always, and keep up your great works.
Nethra: Every data has its bias. My newest post on CI, Crushing It With Competitive Intelligence Analysis: Best Metrics, Reports, has 1800 words of caveats! :)
It is important to understand that panel based data, even with your suggestions for weighting, have a very important sample and sampling bias – much of which simply cannot be accommodated for. Here's just a simple example: No decent-sized corporation on the planet will allow intrusive monitoring software to be on their computers. That entire section of the population – some would say most commercial behavior we exhibit at work – is completely missing.
But it is not from other types of data. They have their own biases, ones that should be understood and accommodated for when making decisions based on those data sources.
Avinash.
I think what you have mentioned is secondary data and often they are historic. They are good to have but does not provide incremental competitive advantage. Why? Because every player in the industry has such resources.
Lots of companies use primary competitive intelligence and they are forward looking. Such primary competitive intelligence has numerous uses in new product planning, brand management, licensing and partnering, opportunity assessment, commercial due diligence etc. One of the groups that I have used in the past are BiopharmaVantage and they are excellent group.
I would love to see an update this post that takes into account the changes in privacy laws and the impact on the CI space.